 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompactRAG: Reducing LLM Calls and Token Overhead in Multi-Hop Question Answering
Feb 05, 2026Retrieval-augmented generation (RAG) has become a key paradigm for knowledge-intensive question answering. However, existing multi-hop RAG systems remain inefficient, as they alternate between retrieval and reasoning at each step, resulting in repeated LLM calls, high token consumption, and unstable entity grounding across hops. We propose CompactRAG, a simple yet effective framework that decouples offline corpus restructuring from online reasoning. In the offline stage, an LLM reads the corpus once and converts it into an atomic QA knowledge base, which represents knowledge as minimal, fine-grained question-answer pairs. In the online stage, complex queries are decomposed and carefully rewritten to preserve entity consistency, and are resolved through dense retrieval followed by RoBERTa-based answer extraction. Notably, during inference, the LLM is invoked only twice in total - once for sub-question decomposition and once for final answer synthesis - regardless of the number of reasoning hops. Experiments on HotpotQA, 2WikiMultiHopQA, and MuSiQue demonstrate that CompactRAG achieves competitive accuracy while substantially reducing token consumption compared to iterative RAG baselines, highlighting a cost-efficient and practical approach to multi-hop reasoning over large knowledge corpora. The implementation is available at GitHub.
Large Language Models for EDA Cloud Job Resource and Lifetime Prediction
Dec 08, 2025The rapid growth of cloud computing in the Electronic Design Automation (EDA) industry has created a critical need for resource and job lifetime prediction to achieve optimal scheduling. Traditional machine learning methods often struggle with the complexity and heterogeneity of EDA workloads, requiring extensive feature engineering and domain expertise. We propose a novel framework that fine-tunes Large Language Models (LLMs) to address this challenge through text-to-text regression. We introduce the scientific notation and prefix filling to constrain the LLM, significantly improving output format reliability. Moreover, we found that full-attention finetuning and inference improves the prediction accuracy of sliding-window-attention LLMs. We demonstrate the effectiveness of our proposed framework on real-world cloud datasets, setting a new baseline for performance prediction in the EDA domain.
On Path to Multimodal Historical Reasoning: HistBench and HistAgent
May 26, 2025Recent advances in large language models (LLMs) have led to remarkable progress across domains, yet their capabilities in the humanities, particularly history, remain underexplored. Historical reasoning poses unique challenges for AI, involving multimodal source interpretation, temporal inference, and cross-linguistic analysis. While general-purpose agents perform well on many existing benchmarks, they lack the domain-specific expertise required to engage with historical materials and questions. To address this gap, we introduce HistBench, a new benchmark of 414 high-quality questions designed to evaluate AI's capacity for historical reasoning and authored by more than 40 expert contributors. The tasks span a wide range of historical problems-from factual retrieval based on primary sources to interpretive analysis of manuscripts and images, to interdisciplinary challenges involving archaeology, linguistics, or cultural history. Furthermore, the benchmark dataset spans 29 ancient and modern languages and covers a wide range of historical periods and world regions. Finding the poor performance of LLMs and other agents on HistBench, we further present HistAgent, a history-specific agent equipped with carefully designed tools for OCR, translation, archival search, and image understanding in History. On HistBench, HistAgent based on GPT-4o achieves an accuracy of 27.54% pass@1 and 36.47% pass@2, significantly outperforming LLMs with online search and generalist agents, including GPT-4o (18.60%), DeepSeek-R1(14.49%) and Open Deep Research-smolagents(20.29% pass@1 and 25.12% pass@2). These results highlight the limitations of existing LLMs and generalist agents and demonstrate the advantages of HistAgent for historical reasoning.
Multi-Robot Pursuit in Parameterized Formation via Imitation Learning
Oct 31, 2024



This paper studies the problem of multi-robot pursuit of how to coordinate a group of defending robots to capture a faster attacker before it enters a protected area. Such operation for defending robots is challenging due to the unknown avoidance strategy and higher speed of the attacker, coupled with the limited communication capabilities of defenders. To solve this problem, we propose a parameterized formation controller that allows defending robots to adapt their formation shape using five adjustable parameters. Moreover, we develop an imitation-learning based approach integrated with model predictive control to optimize these shape parameters. We make full use of these two techniques to enhance the capture capabilities of defending robots through ongoing training. Both simulation and experiment are provided to verify the effectiveness and robustness of our proposed controller. Simulation results show that defending robots can rapidly learn an effective strategy for capturing the attacker, and moreover the learned strategy remains effective across varying numbers of defenders. Experiment results on real robot platforms further validated these findings.
Short Video-based Advertisements Evaluation System: Self-Organizing Learning Approach
Oct 23, 2020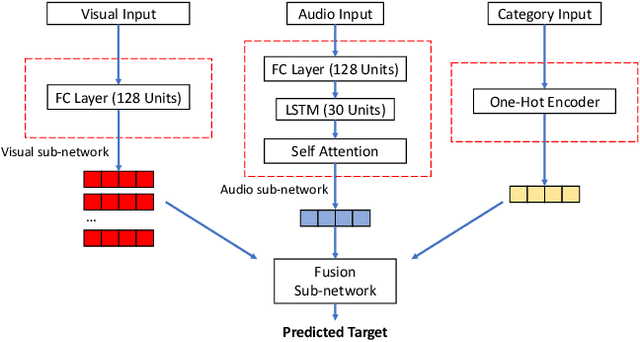
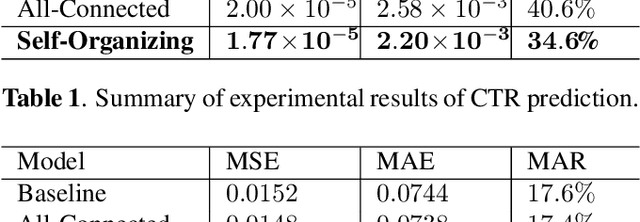
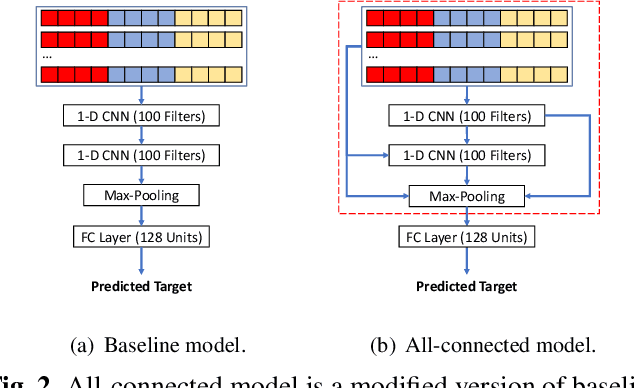
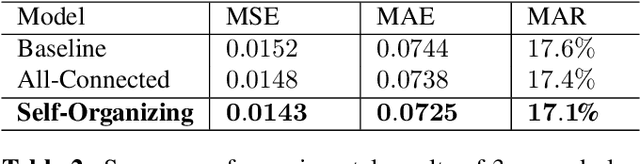
With the rising of short video apps, such as TikTok, Snapchat and Kwai, advertisement in short-term user-generated videos (UGVs) has become a trending form of advertising. Prediction of user behavior without specific user profile is required by advertisers, as they expect to acquire advertisement performance in advance in the scenario of cold start. Current recommender system do not take raw videos as input; additionally, most previous work of Multi-Modal Machine Learning may not deal with unconstrained videos like UGVs. In this paper, we proposed a novel end-to-end self-organizing framework for user behavior prediction. Our model is able to learn the optimal topology of neural network architecture, as well as optimal weights, through training data. We evaluate our proposed method on our in-house dataset. The experimental results reveal that our model achieves the best performance in all our experiments.